I want to give you a headache.
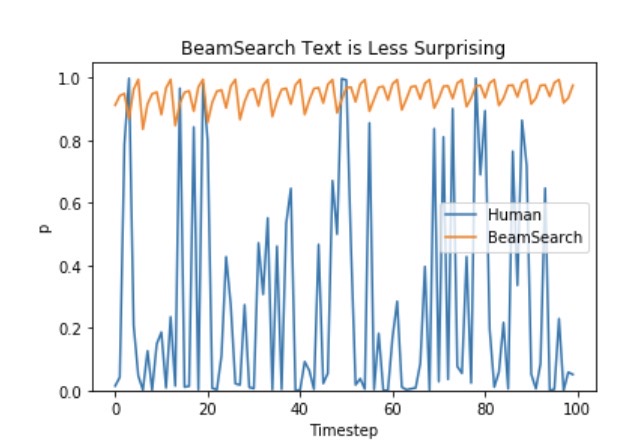
Ari Holtzman et al. (2019) argued that high quality human language does not follow a distribution of high probability next words. In other words, as humans, we want generated text to surprise us and not to be boring/predictable. The authors show this nicely by plotting the probability, a model would give to human text vs. what beam search does.
So, how do you interpret the model that is designed to be unpredictable? [Broken]
#largelanguagemodel