I want to give you [Broken]. Why a small ChatGPT 2 with only 768 numbers to represent 1 meaning can communicate with you?
In general, a consequence of Johnson-Lindenstrauss Lemma, is that the number of vectors you can cram into a space that are nearly perpendicular grows exponentially with the number of dimensions. i.e. \sim \exp(\epsilon * number of dimension)
So specifically, a model with only 768 numbers to represent 1 meaning can store 662k of ideas.
Which makes me wonder, the mathematical checks out. So, why do we need to scale the model from the original GPT-2 124M to hundreds of billions of parameters?
It's not my research direction, but, whatever.
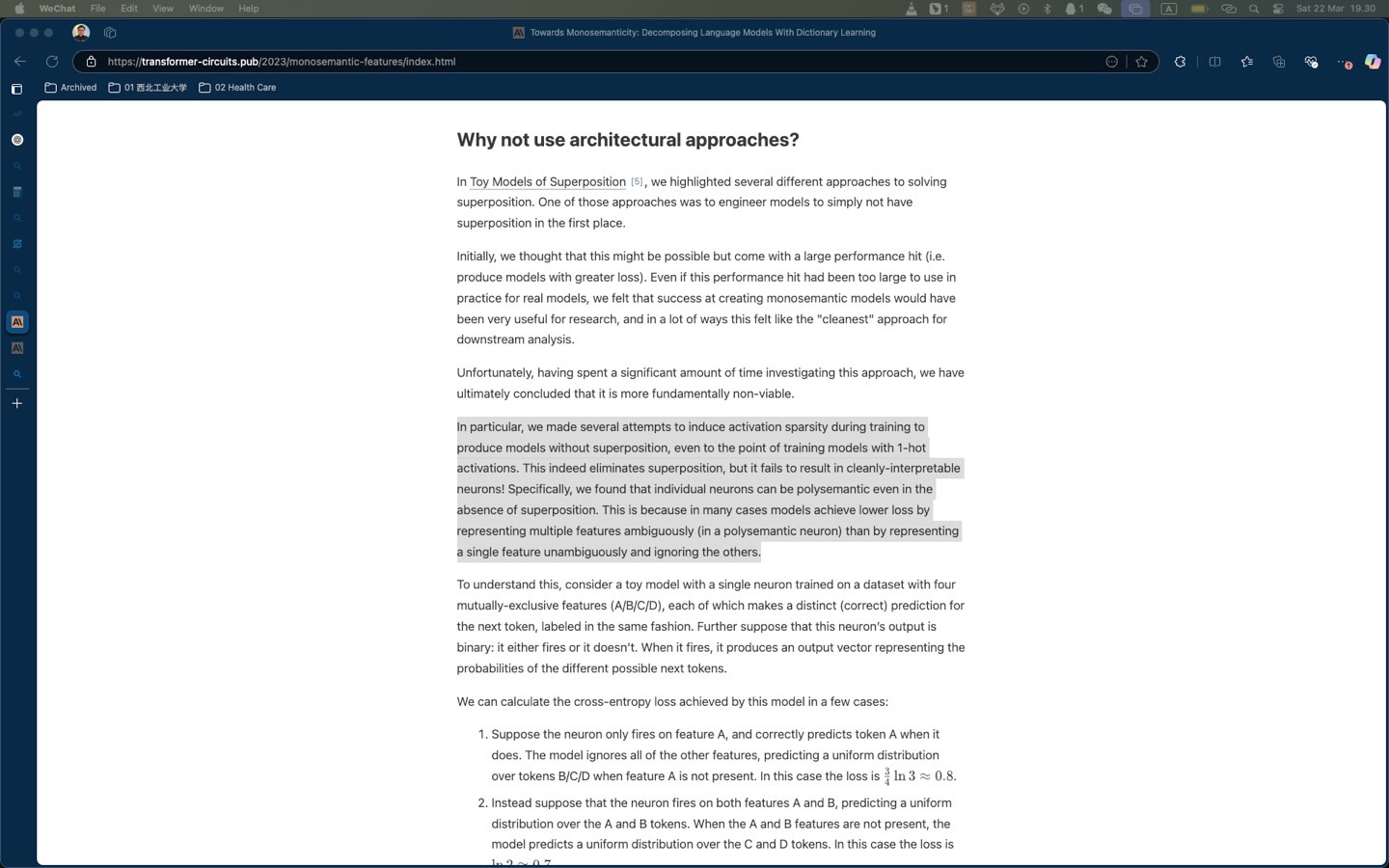
Now, this Johnson-Lindenstrauss Lemma cause interpretability of the model (which is my research direction) very hard. A token will not be represented by 1 single neuron (of the up projection layer output) but specific combinations of neurons (of the up projection layer output).
So, can we prevent the model from having the Johnson-Lindenstrauss Lemma property? We can, but, the consequence is instead of storing 662k of ideas, we will only can store 768 of ideas. And, individual neurons can be polysemantic even in the absence of superposition. Who wants that?
This gives me headache🤕
#largelanguagemodel