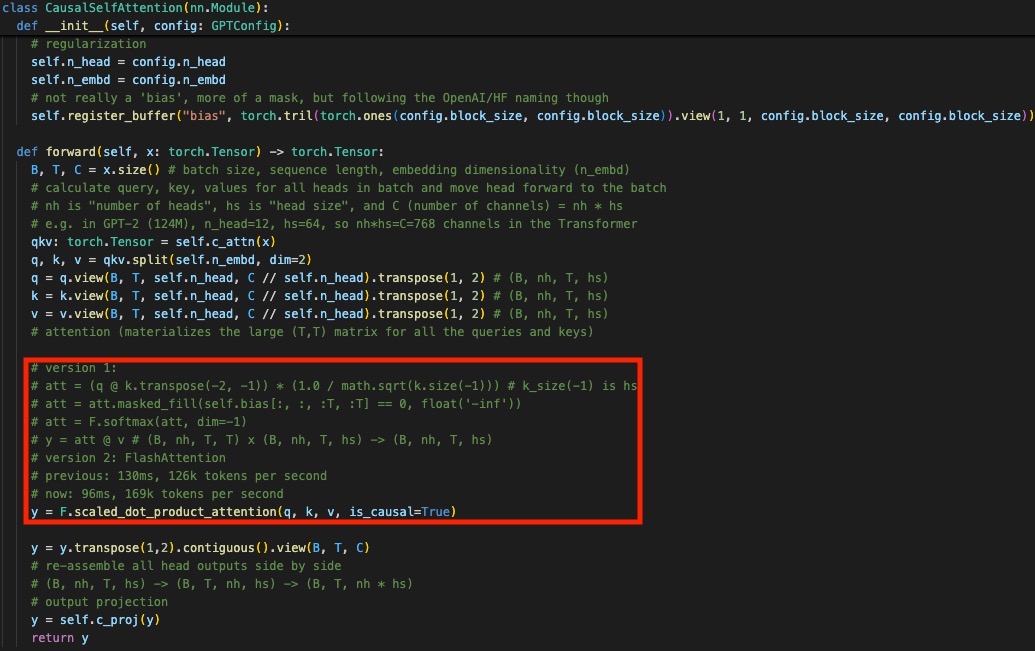
PyTorch support Flash Attention natively with F.scaled_dot_product_attention(q, k, v, is_causal=True).
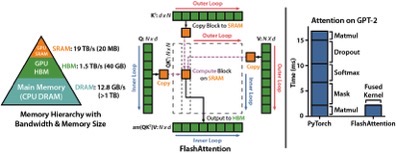
Flash Attention fuses multiple CUDA kernels (Matrix Multiplication, Dropout, Softmax, Mask, Matmul) into one.
124M LLM model, 238k tokens per second with 1x A100 SMX4 or 1.9m with 8x A100 SMX4
#largelanguagemodel